
Facebook Ad Library Scraper
by curious_coder
Need to see what ads your competitors are running on Facebook? This scraper pulls data directly from Facebook's Ad Library, giving you a clear window ...
Opens on Apify.com
About Facebook Ad Library Scraper
Need to see what ads your competitors are running on Facebook? This scraper pulls data directly from Facebook's Ad Library, giving you a clear window into their strategy. It’s the straightforward way to collect ads from search results and specific Facebook pages. I use it to monitor ad copy, creative formats, and targeting trends. It’s fast and doesn’t bog down your system, so you can run it often without a hassle. For the price, it’s incredibly efficient—you get 1000 ad results for less than a dollar. Whether you’re in market research, competitive analysis, or just need to gather ad intelligence, this tool delivers the raw data without any fluff. Just set your search terms or target pages, and it handles the rest.
What does this actor do?
Facebook Ad Library Scraper is a web scraping and automation tool available on the Apify platform. It's designed to help you extract data and automate tasks efficiently in the cloud.
Key Features
- Cloud-based execution - no local setup required
- Scalable infrastructure for large-scale operations
- API access for integration with your applications
- Built-in proxy rotation and anti-blocking measures
- Scheduled runs and webhooks for automation
How to Use
- Click "Try This Actor" to open it on Apify
- Create a free Apify account if you don't have one
- Configure the input parameters as needed
- Run the actor and download your results
Documentation
The Facebook ad library scraper is an Apify actor designed to extract ads from Meta or Facebook ad library and also scrape ads run by given list of facebook pages. With Meta ad library you can search all of the ads currently running across Meta technologies, as well as ads about social issues, elections or politics that have run in the past seven years, Ads that have run anywhere in the EU in the past year. ## Facebook ads library scraper data fields You can get all the fields listed in below table (and more) from this scraper | 💼 Ad ID | 🌐 Ad Archive ID | 🗄️ Archive Types | | ------------------------------- | ----------------------------------- | --------------------------------- | | 📚 Categories | 💻 Contains Digitally Created Media | 📊 Collation Count | | 📊 Collation ID | 💵 Currency | 🕒 End Date | | 🌐 Entity Type | 📈 Gated Type | ❌ Has User Reported | | 🚨 Hidden Safety Data | 🔍 Hide Data Status | 🔄 Impressions With Index | | 🌐 Is AAA Eligible | 🚀 Is Active | 📋 Is Profile Page | | 📜 Page ID | 📜 Page Name | 🌐 Political Countries | | 🌐 Reach Estimate | 🔍 Report Count | 📸 Snapshot of Ads creatives) | | 💰 Spend | 🕒 Start Date | 🚩 State Media Run Label | | 🚀 Publisher Platform | 📚 Menu Items | 🏢 Advertiser | | 📊 Insights | 🚀 AAA Info | ## Features Proxy Support: To enhance reliability and avoid rate limiting issues, the actor supports proxy usage. You can provide a list of proxies that will be rotated automatically to ensure smooth and uninterrupted scraping. Scalability and Performance: The actor is built on the Apify platform, which ensures scalability and excellent performance. It utilizes parallel processing to scrape multiple pages simultaneously, maximizing efficiency and minimizing the overall scraping time. Data Export and Integration: Once the scraping process is complete, you can easily export the extracted data in various formats such as JSON, CSV, or Excel. This allows for seamless integration with other tools and platforms for further analysis and utilization. Automatic Retry and Error Handling: In case of temporary issues like network failures or timeouts, the actor has built-in automatic retry functionality. It intelligently handles errors to ensure a smooth and uninterrupted scraping experience. ## How to scrape facebook ad library 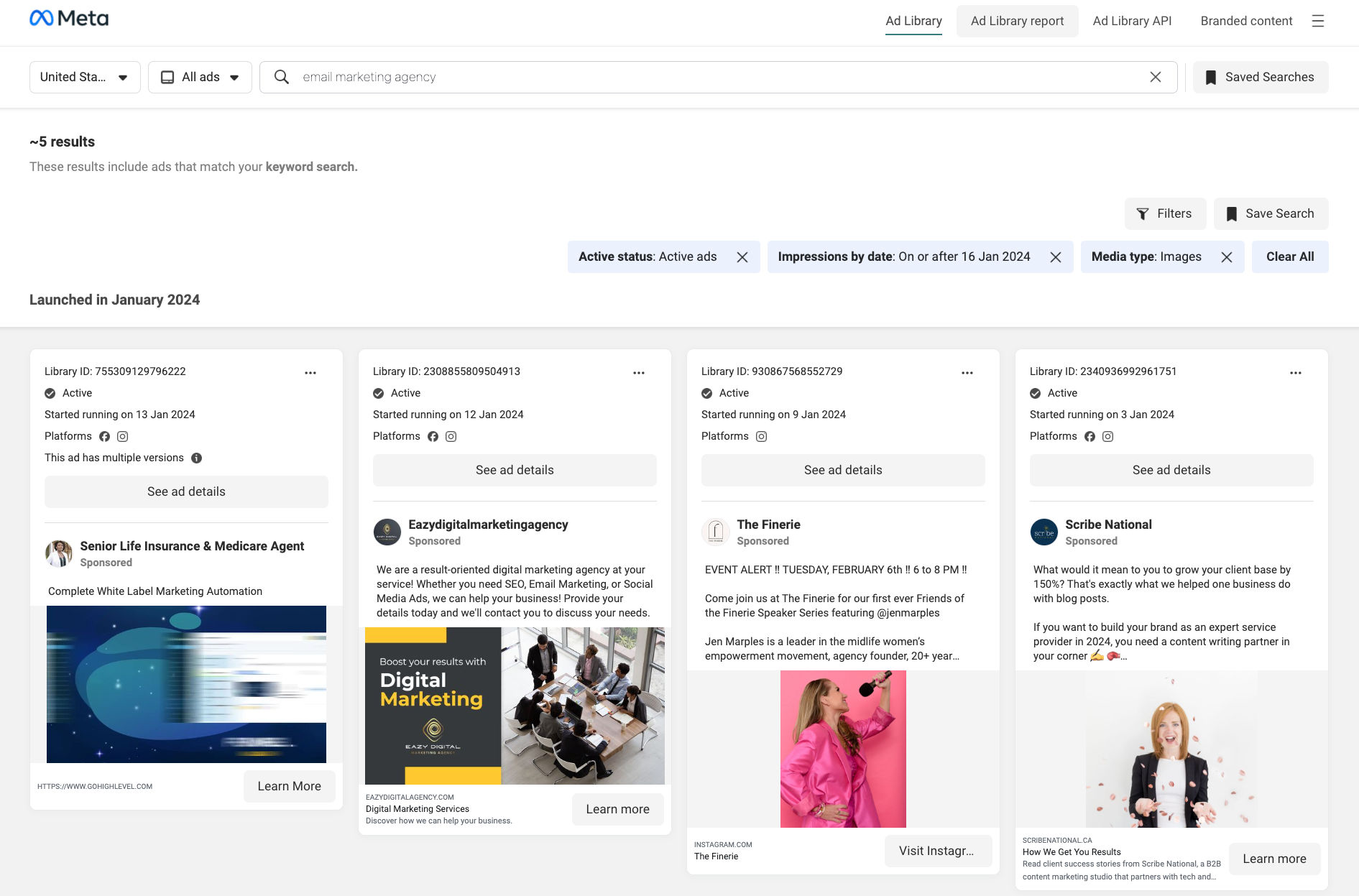 - Visit facebook ad library page and search for ads based on your requirements - Copy the URL from the browser's address bar - Go to Facebook ad library scraper on the Apify platform - Click the Try for free button - Enter the ad library search results page Url - If you want to scrape additional ad details such as EU transparency, EU total reach, etc, enable "Scrape ad details" option - Select a proxy - Click the Start button - When the run has finished, click the Export button to download the ads ## How to scrape ads run by facebook pages
- Visit facebook ad library page and search for ads based on your requirements - Copy the URL from the browser's address bar - Go to Facebook ad library scraper on the Apify platform - Click the Try for free button - Enter the ad library search results page Url - If you want to scrape additional ad details such as EU transparency, EU total reach, etc, enable "Scrape ad details" option - Select a proxy - Click the Start button - When the run has finished, click the Export button to download the ads ## How to scrape ads run by facebook pages 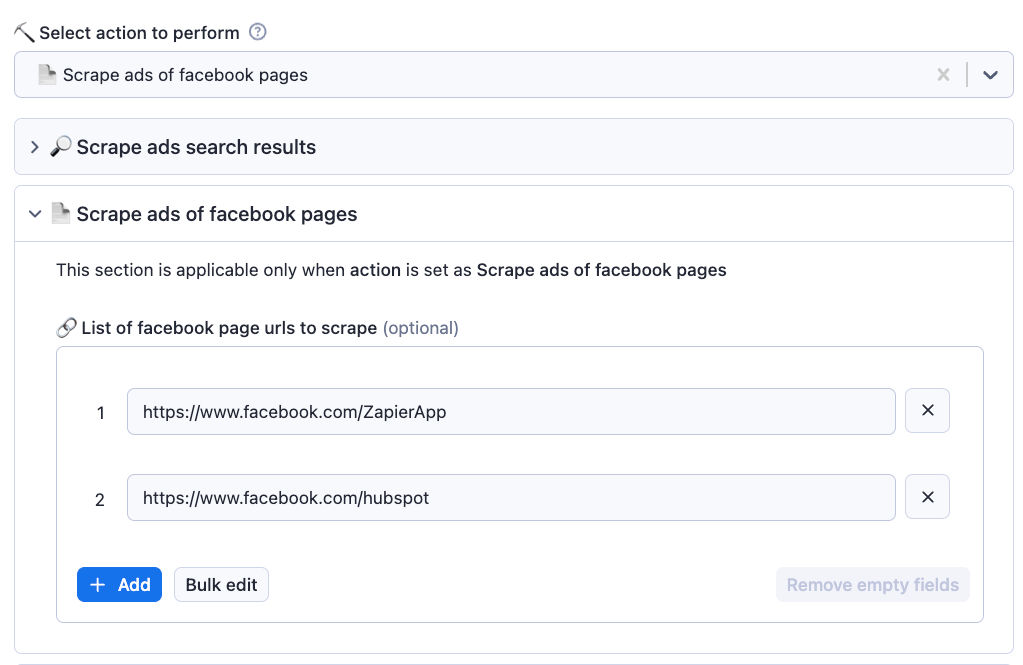 - Create a list of facebook page URLs to scrape ads - Go to actor's input page - Select action to perform as 'Scrape ads of facebook pages' - Go to 'Scrape ads of facebook pages' section and click on 'Bulk edit' and paste the page URLs into the text box - Select a proxy to use and run the scraper ## Sample data Click here to inspect the sample json output of this actor
- Create a list of facebook page URLs to scrape ads - Go to actor's input page - Select action to perform as 'Scrape ads of facebook pages' - Go to 'Scrape ads of facebook pages' section and click on 'Bulk edit' and paste the page URLs into the text box - Select a proxy to use and run the scraper ## Sample data Click here to inspect the sample json output of this actor 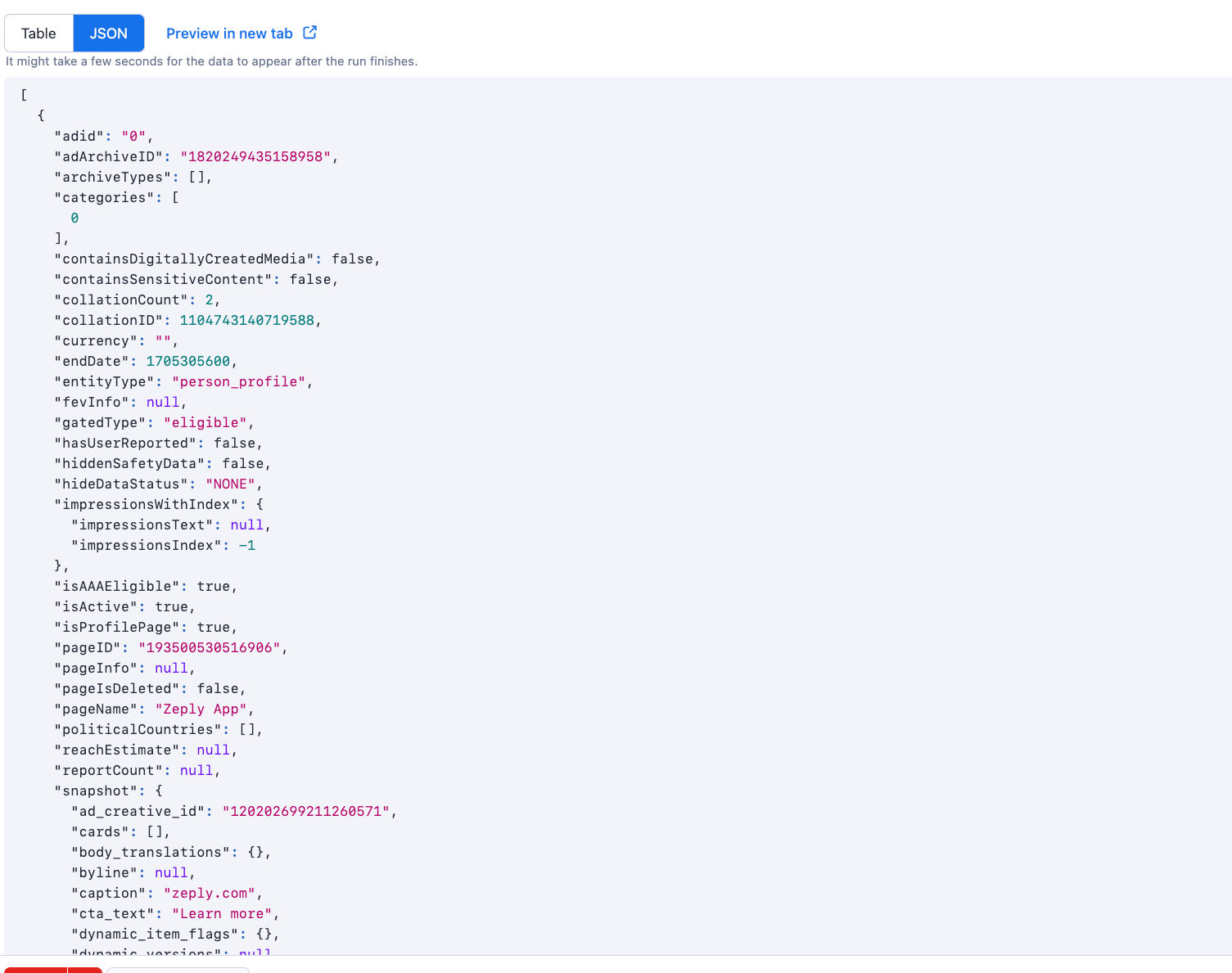 ## Other interesting scrapers We also offer many other interesting scrapers for various use cases at affordable cost. Here are a few - Indeed jobs scraper: Scrape jobs from indeed along with details of company posted the jobs. - Similarweb advanced scraper: Scrape traffic insights and other useful data of websites in bulk. Get keywords, industries, technologies and competitors data. - Apollo company search scraper: Scrape valuable information about companies from apollo company search ## Integrations You can use Make to integrate Facebook ad library scraper to any other SaaS platform by designing your own automation flows. ## How to extract ads data from Facebook using API? You can also run the scraper using API and get the collected data using the API. For more information, Go to Facebook ad library scraper API integration page. Here is an example of fetching the ads data via API using Postman:
## Other interesting scrapers We also offer many other interesting scrapers for various use cases at affordable cost. Here are a few - Indeed jobs scraper: Scrape jobs from indeed along with details of company posted the jobs. - Similarweb advanced scraper: Scrape traffic insights and other useful data of websites in bulk. Get keywords, industries, technologies and competitors data. - Apollo company search scraper: Scrape valuable information about companies from apollo company search ## Integrations You can use Make to integrate Facebook ad library scraper to any other SaaS platform by designing your own automation flows. ## How to extract ads data from Facebook using API? You can also run the scraper using API and get the collected data using the API. For more information, Go to Facebook ad library scraper API integration page. Here is an example of fetching the ads data via API using Postman: 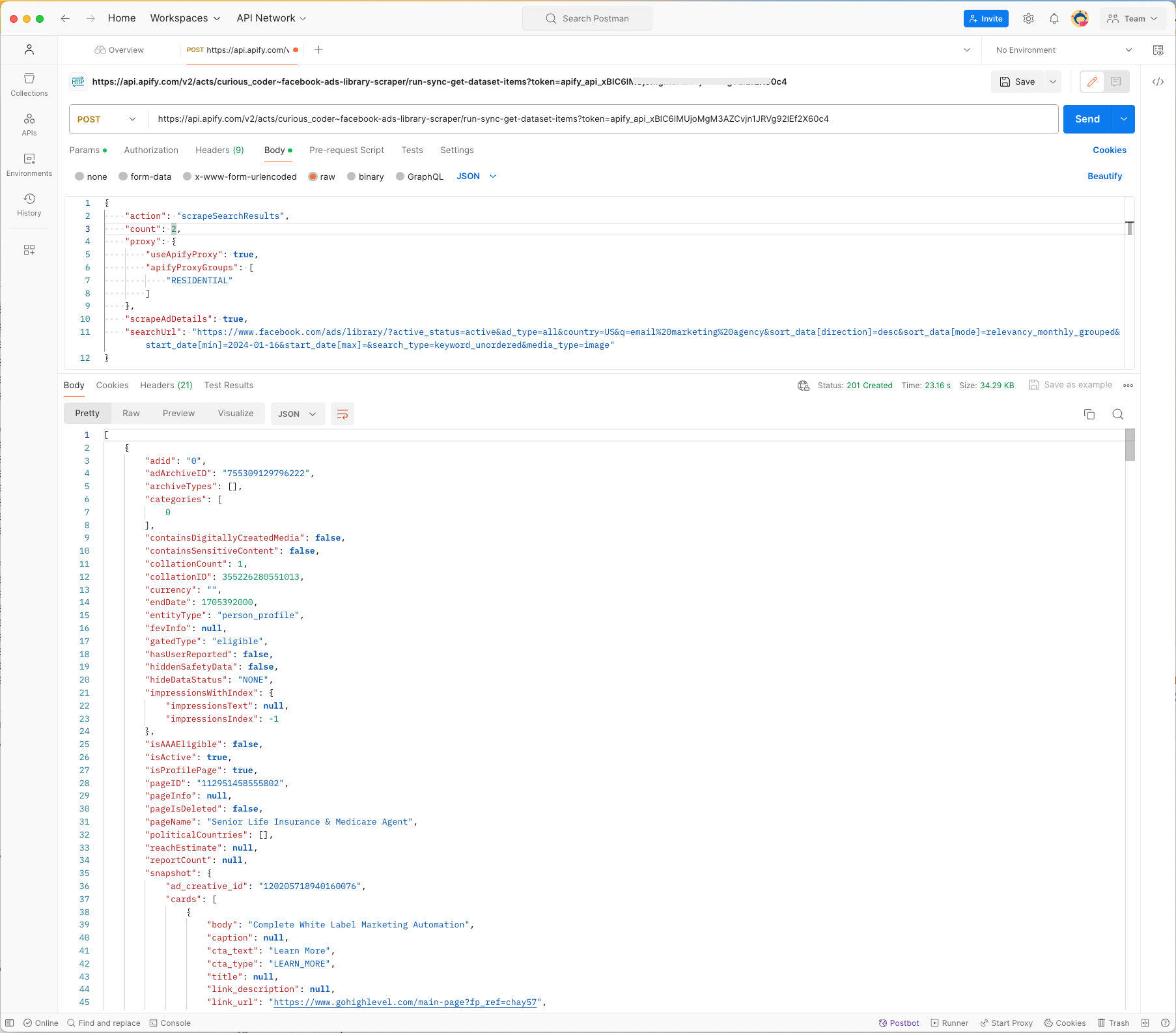 ## How much will it cost me to scrape Facebook ads ? Based on historical data our scraper costs an average of $0.2 per thousand Facebook ads as usage credits. You can scrape upto 25k Facebook ads per month with Apify starter plan ## Is it legal to scrape facebook ad library ? Our scrapers are ethical and do not extract any private user data, such as email addresses, gender, or location. They only extract what the user has chosen to share publicly. We therefore believe that our scrapers, when used for ethical purposes by Apify users, are safe. However, you should be aware that your results could contain personal data. Personal data is protected by the GDPR in the European Union and by other regulations around the world. You should not scrape personal data unless you have a legitimate reason to do so. If you're unsure whether your reason is legitimate, consult your lawyers. You can also read our blog post on the legality of web scraping ## Your feedback We’re always working on improving the performance of our Actors. So if you’ve got any technical feedback for this scraper or simply found a bug, please create an issue on the actor’s Issues tab in Apify Console For additional information you can email us at heycuriouscoder@gmail.com
## How much will it cost me to scrape Facebook ads ? Based on historical data our scraper costs an average of $0.2 per thousand Facebook ads as usage credits. You can scrape upto 25k Facebook ads per month with Apify starter plan ## Is it legal to scrape facebook ad library ? Our scrapers are ethical and do not extract any private user data, such as email addresses, gender, or location. They only extract what the user has chosen to share publicly. We therefore believe that our scrapers, when used for ethical purposes by Apify users, are safe. However, you should be aware that your results could contain personal data. Personal data is protected by the GDPR in the European Union and by other regulations around the world. You should not scrape personal data unless you have a legitimate reason to do so. If you're unsure whether your reason is legitimate, consult your lawyers. You can also read our blog post on the legality of web scraping ## Your feedback We’re always working on improving the performance of our Actors. So if you’ve got any technical feedback for this scraper or simply found a bug, please create an issue on the actor’s Issues tab in Apify Console For additional information you can email us at heycuriouscoder@gmail.com
Categories
Common Use Cases
Market Research
Gather competitive intelligence and market data
Lead Generation
Extract contact information for sales outreach
Price Monitoring
Track competitor pricing and product changes
Content Aggregation
Collect and organize content from multiple sources
Ready to Get Started?
Try Facebook Ad Library Scraper now on Apify. Free tier available with no credit card required.
Start Free TrialActor Information
- Developer
- curious_coder
- Pricing
- Paid
- Total Runs
- 7,787,501
- Active Users
- 14,003
Related Actors

🏯 Tweet Scraper V2 - X / Twitter Scraper
by apidojo

Instagram Scraper
by apify

TikTok Scraper
by clockworks

Instagram Profile Scraper
by apify
Apify provides a cloud platform for web scraping, data extraction, and automation. Build and run web scrapers in the cloud.
Learn more about ApifyNeed Professional Help?
Couldn't solve your problem? Hire a verified specialist on Fiverr to get it done quickly and professionally.
Trusted by millions | Money-back guarantee | 24/7 Support