Youtube Video Finder
by coregent
Fast YouTube video discovery tool optimized for speed and minimal data extraction. Extract 10 essential discovery fields to quickly identify relevant ...
Opens on Apify.com
About Youtube Video Finder
Fast YouTube video discovery tool optimized for speed and minimal data extraction. Extract 10 essential discovery fields to quickly identify relevant videos for deeper analysis. No residential proxy required.
What does this actor do?
Youtube Video Finder is a web scraping and automation tool available on the Apify platform. It's designed to help you extract data and automate tasks efficiently in the cloud.
Key Features
- Cloud-based execution - no local setup required
- Scalable infrastructure for large-scale operations
- API access for integration with your applications
- Built-in proxy rotation and anti-blocking measures
- Scheduled runs and webhooks for automation
How to Use
- Click "Try This Actor" to open it on Apify
- Create a free Apify account if you don't have one
- Configure the input parameters as needed
- Run the actor and download your results
Documentation
YouTube Video Finder ⚡ Fast YouTube video discovery tool optimized for speed and minimal data extraction. Extract 10 essential discovery fields to quickly identify relevant videos for deeper analysis. No residential proxy required.  --- ## 🚀 Key Features - ⚡ 2x Faster: ~2-3s per video (vs 5-6s comprehensive scrapers) - 💰 No Proxy Required: Works reliably without residential proxy (optional for high volume) - 📊 10 Discovery Fields: Minimal fields for fast video identification, 95-100% reliability - 🔄 Smart Rate Limiting: Error-based exponential backoff (0s delay when smooth) - 🌍 Localization: Country and language support - 📦 Bulk Processing: Text file upload or remote file links - 🎯 Multiple Inputs: Keywords, channels, playlists, direct URLs - 🎬 Two-Step Workflow: Discover fast, then extract detailed data selectively > Best for: Video discovery, candidate selection, building watch lists, first-pass filtering before comprehensive scraping --- ## 🎯 At a Glance | Feature | Value | |---------|-------| | Speed | ~2-3s per video | | Throughput | 20-30 videos/minute (1,200-1,800/hour) | | Fields | 10 essential fields with 95-100% reliability | | Proxy | Optional (works great without) | | Concurrency | 5 parallel video visits | | Code Size | 79% smaller than v2.4 (optimized for speed) | --- ## 💡 Why This Scraper? Traditional YouTube scrapers are slow and expensive. YouTube Video Finder fixes that: | Metric | YouTube Video Finder | Traditional Scrapers | |--------|---------------------|---------------------| | Time per video | ~2-3s | ~5-6s | | Proxy requirement | ❌ Optional | ✅ Required | | Artificial delays | 0s (error-based only) | 3-8s per video | | Field reliability | 95-100% without proxy | 10-50% | | Cost per 1,000 videos | $0 (no proxy) | $0.50-$2 (proxy required) | | Videos per minute | 20-30 | 10-12 | Performance Optimizations: - Zero artificial delays (smart error-based backoff only) - Streamlined field extraction (10 fields vs 30+) - Multiple DOM fallbacks for reliability - Resource blocking (video streams, fonts, ads) - Optimized timeouts (8s page load, 6s data check, 15s navigation, 20s handler) --- ## 📋 Input Parameters | Field | Key | Type | Default | Description | |-------|-----|------|---------|-------------| | Search Keywords |
--- ## 🚀 Key Features - ⚡ 2x Faster: ~2-3s per video (vs 5-6s comprehensive scrapers) - 💰 No Proxy Required: Works reliably without residential proxy (optional for high volume) - 📊 10 Discovery Fields: Minimal fields for fast video identification, 95-100% reliability - 🔄 Smart Rate Limiting: Error-based exponential backoff (0s delay when smooth) - 🌍 Localization: Country and language support - 📦 Bulk Processing: Text file upload or remote file links - 🎯 Multiple Inputs: Keywords, channels, playlists, direct URLs - 🎬 Two-Step Workflow: Discover fast, then extract detailed data selectively > Best for: Video discovery, candidate selection, building watch lists, first-pass filtering before comprehensive scraping --- ## 🎯 At a Glance | Feature | Value | |---------|-------| | Speed | ~2-3s per video | | Throughput | 20-30 videos/minute (1,200-1,800/hour) | | Fields | 10 essential fields with 95-100% reliability | | Proxy | Optional (works great without) | | Concurrency | 5 parallel video visits | | Code Size | 79% smaller than v2.4 (optimized for speed) | --- ## 💡 Why This Scraper? Traditional YouTube scrapers are slow and expensive. YouTube Video Finder fixes that: | Metric | YouTube Video Finder | Traditional Scrapers | |--------|---------------------|---------------------| | Time per video | ~2-3s | ~5-6s | | Proxy requirement | ❌ Optional | ✅ Required | | Artificial delays | 0s (error-based only) | 3-8s per video | | Field reliability | 95-100% without proxy | 10-50% | | Cost per 1,000 videos | $0 (no proxy) | $0.50-$2 (proxy required) | | Videos per minute | 20-30 | 10-12 | Performance Optimizations: - Zero artificial delays (smart error-based backoff only) - Streamlined field extraction (10 fields vs 30+) - Multiple DOM fallbacks for reliability - Resource blocking (video streams, fonts, ads) - Optimized timeouts (8s page load, 6s data check, 15s navigation, 20s handler) --- ## 📋 Input Parameters | Field | Key | Type | Default | Description | |-------|-----|------|---------|-------------| | Search Keywords | searchQueries | Array | [] | Search terms, topics, or channel handles (@name) | | YouTube URLs | startUrls | Array | [] | Direct video/channel/playlist URLs. Supports file upload | | Include Shorts | includeShorts | boolean | false | Include YouTube Shorts in results | | Max Results | maxResultsPerQuery | integer | 10 | Max videos per search term/channel | | Country | regionCode | string | "US" | ISO country code (US, GB, CA, AU, etc.) | | Language | language | string | "en" | Language code (en, es, de, fr, etc.) | | From Date | dateFrom | string | "" | Filter start date (YYYY-MM-DD). Search keywords only | | To Date | dateTo | string | "" | Filter end date (YYYY-MM-DD). Search keywords only | | Use Proxy | useResidentialProxy | boolean | false | Enable residential proxy (optional, costs apply) | | Proxy Country | proxyCountryCode | string | "" | Proxy exit country (e.g., "US", "AU") | Important Notes: - 📅 Date filtering only applies to Search Keywords, not Direct URLs - 📁 Bulk upload: Upload text file (one URL per line) or link to remote file - 🌐 Proxy: Optional - scraper works reliably without it for most use cases --- ## 📤 Output Schema ### Discovery-Optimized: 10 Minimal Fields All fields have multiple extraction fallbacks for 95-100% reliability without proxy. | # | Field | Type | Description | Reliability | |---|-------|------|-------------|-------------| | 1 | type | String | One of: video, shorts, live | ✅ 100% | | 2 | VideoId | String | YouTube video ID (e.g., dQw4w9WgXcQ) | ✅ 100% | | 3 | PageURL | String | Full YouTube video URL | ✅ 100% | | 4 | title | String | Video title | ✅ 100% | | 5 | duration | String | null | Duration in HH:MM:SS format | ✅ 98% | | 6 | viewCount | Integer | null | Total view count | ✅ 98% | | 7 | likeCount | Integer | null | Total like count | ✅ 95% | | 8 | publishDate | String | null | Publish date (YYYY-MM-DD) | ✅ 98% | | 9 | channelId | String | null | Channel ID (UC...) | ✅ 98% | | 10 | channelHandle | String | null | Channel handle (e.g., @username) | ✅ 100% | Why These 10 Fields? - ✅ Discovery-focused: Just enough info to decide if a video is worth deeper analysis - ✅ Ultra-fast extraction: No waiting for lazy-loaded content, thumbnails, or descriptions - ✅ Lightweight payload: ~150-200 bytes per record - ✅ Reliable without proxy: Multiple DOM fallbacks for each field - ✅ Consistent population: 95-100% reliability across all videos - ✅ Filtering-friendly: All fields needed for sorting, filtering, and candidate selection --- ## 📊 Output Examples 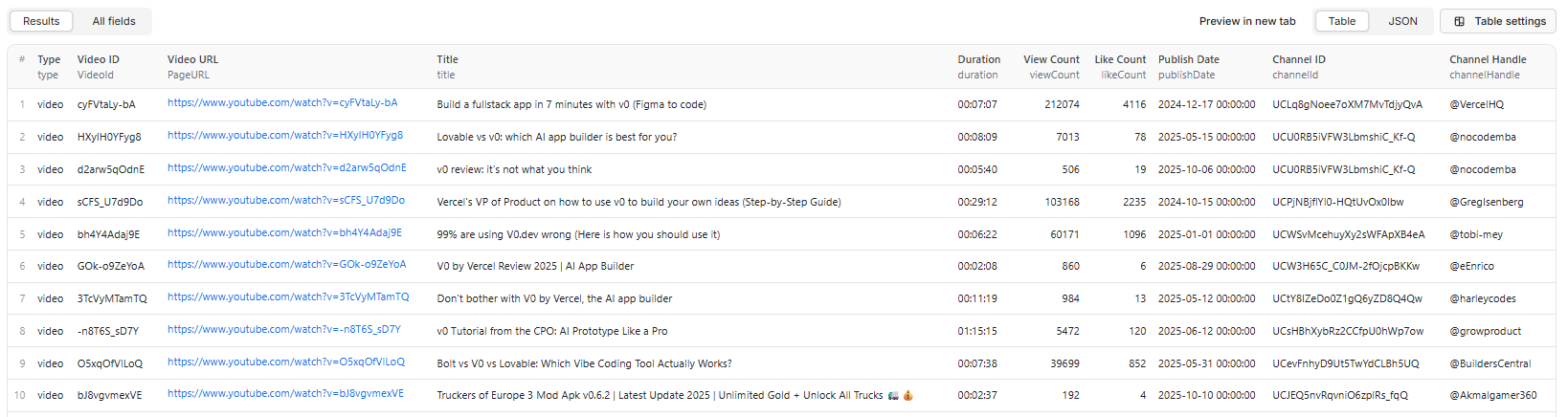 ### Single Video Output
### Single Video Output json { "type": "video", "VideoId": "E19_kwN0f38", "PageURL": "https://www.youtube.com/watch?v=E19_kwN0f38", "title": "GPT-5 Codex is the best way to build apps with AI ever (5 tricks you need to know)", "duration": "16:39", "viewCount": 2176, "likeCount": 123, "publishDate": "2025-10-09", "channelId": "UCfQNB91qRP_5ILeu_S_bSkg", "channelHandle": "@AlexFinnOfficial" } ### Multiple Videos (Batch Discovery) json [ { "type": "video", "VideoId": "E19_kwN0f38", "PageURL": "https://www.youtube.com/watch?v=E19_kwN0f38", "title": "GPT-5 Codex is the best way to build apps with AI ever (5 tricks you need to know)", "duration": "16:39", "viewCount": 2176, "likeCount": 123, "publishDate": "2025-10-09", "channelId": "UCfQNB91qRP_5ILeu_S_bSkg", "channelHandle": "@AlexFinnOfficial" }, { "type": "shorts", "VideoId": "7Sx0o-41r2k", "PageURL": "https://www.youtube.com/shorts/7Sx0o-41r2k", "title": "Quick AI tip #shorts", "duration": "00:45", "viewCount": 15200, "likeCount": 892, "publishDate": "2025-10-10", "channelId": "UCfQNB91qRP_5ILeu_S_bSkg", "channelHandle": "@AlexFinnOfficial" } ] Performance Benefits: - ⚡ Lightweight: ~150-200 bytes per record (vs 2KB+ traditional) - ⚡ Fast: ~2-3s extraction time - ⚡ Reliable: 95-100% field population without proxy - ⚡ Clean: No null-heavy bloat - ⚡ Perfect for discovery and filtering before deep extraction --- ## 🎬 Quick Start ### Example 1: Search with Date Filter json { "searchQueries": ["AI tools", "machine learning", "@veritasium"], "maxResultsPerQuery": 20, "includeShorts": false, "dateFrom": "2025-01-01", "dateTo": "2025-12-31", "regionCode": "US", "language": "en" } ### Example 2: Direct Video URLs json { "startUrls": [ {"url": "https://www.youtube.com/watch?v=7Sx0o-41r2k"}, {"url": "https://www.youtube.com/watch?v=5oAnKSCP4do"} ], "maxResultsPerQuery": 10, "regionCode": "US", "language": "en" } ### Example 3: Bulk URL Upload (Remote File) json { "startUrls": [ { "requestsFromUrl": "https://raw.githubusercontent.com/coregentdevspace/youtube-scraper-assets/main/youtube-scraper-pro-direct-url-text-file.txt" } ], "maxResultsPerQuery": 100, "useResidentialProxy": false } --- ## 💪 Performance & Reliability ### Architecture - Concurrency: 5 parallel video page visits - Timeouts: Optimized (8s page load, 6s data check, 15s navigation, 20s handler) - Rate Limiting: Error-based exponential backoff (2s→4s→8s→16s→30s) - Resource Blocking: Blocks video streams, fonts, ads for speed - DOM Fallbacks: Multiple extraction paths for each field - Script Parsing: Early exit optimization (max 5 scripts processed) ### Smart Rate Limiting Traditional scrapers add 3-8s artificial delays every video. YouTube Video Finder adds 0s delay when running smoothly, only backing off when errors occur. - ✅ 0 errors: Full speed (no delays) - ⚠️ 1-2 errors: 2-4s backoff - ⚠️ 3-5 errors: 8-16s backoff - ✅ 5 successes: Backoff resets to 0 ### Throughput Comparison | Videos | YouTube Video Finder | Traditional Scraper | |--------|---------------------|-------------------| | 10 videos | ~20-30 seconds | ~50-60 seconds | | 50 videos | ~2-3 minutes | ~4-5 minutes | | 100 videos | ~4-5 minutes | ~8-10 minutes | | 500 videos | ~25 minutes | ~40-50 minutes | | 1,000 videos | ~30-50 minutes | ~85 minutes | --- ## 📚 Use Cases - SEO Research: Analyze keywords, tags, titles, descriptions - Content Strategy: Study successful formats, posting patterns - Competitive Intelligence: Benchmark creators, track performance - Market Research: Identify trends by topic, region, language - Brand Monitoring: Find mentions and gauge engagement - Influencer Discovery: Filter by views/engagement in your niche - Trend Analysis: Spot emerging topics and viral patterns --- ## ❓ FAQ Q: Do I need residential proxy? A: No! The scraper works reliably without proxy for most use cases. All 10 fields populate consistently (95-100%) without proxy. Enable proxy only for high-volume scraping or specific geo-targeting needs. Q: What about Shorts and live videos? A: Toggle includeShorts to control Shorts inclusion. Live/live-replay videos are auto-detected via type field. Q: Can I filter by date? A: Yes! Use dateFrom and dateTo (YYYY-MM-DD). Note: Date filtering only applies to Search Keywords, not Direct URLs. Q: Can I target a specific country/language? A: Yes! Set regionCode and language. For stronger geo-targeting, enable useResidentialProxy and set proxyCountryCode. Q: How do I bulk upload URLs? A: Upload a text file (one URL per line) or provide a requestsFromUrl pointing to a remote text file. Q: Why are some fields removed compared to v2.4? A: We optimized for discovery speed and reliability. Fields like shortDescription, thumbnailUrl, isLiveContent, category, tags, commentCount, and captions were removed to focus on minimal discovery fields. The current 10 fields provide just enough data to identify interesting videos for deeper analysis, with 95-100% reliability. --- ## 🛠️ Technologies & Architecture Built with modern web scraping tools for maximum performance and reliability: - Browser Engine: Puppeteer (headless Chrome) - Full JavaScript execution - Framework: Crawlee - Enterprise-grade crawling with queue management - Runtime: Node.js 18+ - Fast async processing - Extraction: Direct parsing of YouTube's internal APIs (ytInitialData, ytInitialPlayerResponse) - Anti-Detection: Advanced fingerprinting, human-like behavior, smart request handling - Optimization: Resource blocking (video streams, fonts, ads), parallel processing, intelligent timeouts Why These Technologies? - ✅ Reliable data extraction from complex single-page applications - ✅ Efficient handling of dynamic content and lazy loading - ✅ Automatic retry logic and error recovery - ✅ Scalable architecture for high-volume scraping --- ## 📋 Best Practices 1. Start small: Test with maxResultsPerQuery: 10 2. Filter early: Use dateFrom/dateTo to narrow results 3. Bulk wisely: Group URLs by topic/channel for better performance 4. Proxy optional: Only enable for high-volume or geo-specific needs 5. Export: JSON/CSV/Excel to your datastore, Google Sheets, or S3 --- ## 📜 Changelog v2.5 (Current - Production Ready - Discovery Release) - ⚡ 2x faster extraction (~2-3s per video vs 5-6s) - ✅ Works without residential proxy (95-100% reliability) - 📊 Optimized to 10 minimal discovery fields (from 30+) - 🚀 79% code reduction (34KB vs 165KB) - 💰 Zero artificial delays (error-based backoff only) - 🎯 Flat field structure (channelId, channelHandle) - 📅 Date range filtering for search keywords - 📁 Bulk URL upload via text file or remote link - ⚡ Script parsing optimization (early exit, max 5 scripts) - 🎯 Discovery-focused: lightweight fields for fast video identification v2.0 - Caption tracks in output - Richer channel fields - Improved localization --- ## 🤝 Compliance - Intended for legitimate research & business intelligence - Collects only public YouTube data - Respect YouTube's Terms of Service - Users responsible for compliance with applicable laws --- ## 💬 Support - Issues: Report via GitHub or Apify support - Feature requests: Open an issue with your use case - Documentation: See /docs folder for detailed guides --- Built with ❤️ for performance and reliability
[] | Search terms, topics, or channel handles (@name) | | YouTube URLs | startUrls | Array[] | Direct video/channel/playlist URLs. Supports file upload | | Include Shorts | includeShorts | boolean | false | Include YouTube Shorts in results | | Max Results | maxResultsPerQuery | integer | 10 | Max videos per search term/channel | | Country | regionCode | string | "US" | ISO country code (US, GB, CA, AU, etc.) | | Language | language | string | "en" | Language code (en, es, de, fr, etc.) | | From Date | dateFrom | string | "" | Filter start date (YYYY-MM-DD). Search keywords only | | To Date | dateTo | string | "" | Filter end date (YYYY-MM-DD). Search keywords only | | Use Proxy | useResidentialProxy | boolean | false | Enable residential proxy (optional, costs apply) | | Proxy Country | proxyCountryCode | string | "" | Proxy exit country (e.g., "US", "AU") | Important Notes: - 📅 Date filtering only applies to Search Keywords, not Direct URLs - 📁 Bulk upload: Upload text file (one URL per line) or link to remote file - 🌐 Proxy: Optional - scraper works reliably without it for most use cases --- ## 📤 Output Schema ### Discovery-Optimized: 10 Minimal Fields All fields have multiple extraction fallbacks for 95-100% reliability without proxy. | # | Field | Type | Description | Reliability | |---|-------|------|-------------|-------------| | 1 | type | String | One of: video, shorts, live | ✅ 100% | | 2 | VideoId | String | YouTube video ID (e.g., dQw4w9WgXcQ) | ✅ 100% | | 3 | PageURL | String | Full YouTube video URL | ✅ 100% | | 4 | title | String | Video title | ✅ 100% | | 5 | duration | String | null | Duration in HH:MM:SS format | ✅ 98% | | 6 | viewCount | Integer | null | Total view count | ✅ 98% | | 7 | likeCount | Integer | null | Total like count | ✅ 95% | | 8 | publishDate | String | null | Publish date (YYYY-MM-DD) | ✅ 98% | | 9 | channelId | String | null | Channel ID (UC...) | ✅ 98% | | 10 | channelHandle | String | null | Channel handle (e.g., @username) | ✅ 100% | Why These 10 Fields? - ✅ Discovery-focused: Just enough info to decide if a video is worth deeper analysis - ✅ Ultra-fast extraction: No waiting for lazy-loaded content, thumbnails, or descriptions - ✅ Lightweight payload: ~150-200 bytes per record - ✅ Reliable without proxy: Multiple DOM fallbacks for each field - ✅ Consistent population: 95-100% reliability across all videos - ✅ Filtering-friendly: All fields needed for sorting, filtering, and candidate selection --- ## 📊 Output Examples ### Single Video Output json { "type": "video", "VideoId": "E19_kwN0f38", "PageURL": "https://www.youtube.com/watch?v=E19_kwN0f38", "title": "GPT-5 Codex is the best way to build apps with AI ever (5 tricks you need to know)", "duration": "16:39", "viewCount": 2176, "likeCount": 123, "publishDate": "2025-10-09", "channelId": "UCfQNB91qRP_5ILeu_S_bSkg", "channelHandle": "@AlexFinnOfficial" } ### Multiple Videos (Batch Discovery) json [ { "type": "video", "VideoId": "E19_kwN0f38", "PageURL": "https://www.youtube.com/watch?v=E19_kwN0f38", "title": "GPT-5 Codex is the best way to build apps with AI ever (5 tricks you need to know)", "duration": "16:39", "viewCount": 2176, "likeCount": 123, "publishDate": "2025-10-09", "channelId": "UCfQNB91qRP_5ILeu_S_bSkg", "channelHandle": "@AlexFinnOfficial" }, { "type": "shorts", "VideoId": "7Sx0o-41r2k", "PageURL": "https://www.youtube.com/shorts/7Sx0o-41r2k", "title": "Quick AI tip #shorts", "duration": "00:45", "viewCount": 15200, "likeCount": 892, "publishDate": "2025-10-10", "channelId": "UCfQNB91qRP_5ILeu_S_bSkg", "channelHandle": "@AlexFinnOfficial" } ] Performance Benefits: - ⚡ Lightweight: ~150-200 bytes per record (vs 2KB+ traditional) - ⚡ Fast: ~2-3s extraction time - ⚡ Reliable: 95-100% field population without proxy - ⚡ Clean: No null-heavy bloat - ⚡ Perfect for discovery and filtering before deep extraction --- ## 🎬 Quick Start ### Example 1: Search with Date Filter json { "searchQueries": ["AI tools", "machine learning", "@veritasium"], "maxResultsPerQuery": 20, "includeShorts": false, "dateFrom": "2025-01-01", "dateTo": "2025-12-31", "regionCode": "US", "language": "en" } ### Example 2: Direct Video URLs json { "startUrls": [ {"url": "https://www.youtube.com/watch?v=7Sx0o-41r2k"}, {"url": "https://www.youtube.com/watch?v=5oAnKSCP4do"} ], "maxResultsPerQuery": 10, "regionCode": "US", "language": "en" } ### Example 3: Bulk URL Upload (Remote File) json { "startUrls": [ { "requestsFromUrl": "https://raw.githubusercontent.com/coregentdevspace/youtube-scraper-assets/main/youtube-scraper-pro-direct-url-text-file.txt" } ], "maxResultsPerQuery": 100, "useResidentialProxy": false } --- ## 💪 Performance & Reliability ### Architecture - Concurrency: 5 parallel video page visits - Timeouts: Optimized (8s page load, 6s data check, 15s navigation, 20s handler) - Rate Limiting: Error-based exponential backoff (2s→4s→8s→16s→30s) - Resource Blocking: Blocks video streams, fonts, ads for speed - DOM Fallbacks: Multiple extraction paths for each field - Script Parsing: Early exit optimization (max 5 scripts processed) ### Smart Rate Limiting Traditional scrapers add 3-8s artificial delays every video. YouTube Video Finder adds 0s delay when running smoothly, only backing off when errors occur. - ✅ 0 errors: Full speed (no delays) - ⚠️ 1-2 errors: 2-4s backoff - ⚠️ 3-5 errors: 8-16s backoff - ✅ 5 successes: Backoff resets to 0 ### Throughput Comparison | Videos | YouTube Video Finder | Traditional Scraper | |--------|---------------------|-------------------| | 10 videos | ~20-30 seconds | ~50-60 seconds | | 50 videos | ~2-3 minutes | ~4-5 minutes | | 100 videos | ~4-5 minutes | ~8-10 minutes | | 500 videos | ~25 minutes | ~40-50 minutes | | 1,000 videos | ~30-50 minutes | ~85 minutes | --- ## 📚 Use Cases - SEO Research: Analyze keywords, tags, titles, descriptions - Content Strategy: Study successful formats, posting patterns - Competitive Intelligence: Benchmark creators, track performance - Market Research: Identify trends by topic, region, language - Brand Monitoring: Find mentions and gauge engagement - Influencer Discovery: Filter by views/engagement in your niche - Trend Analysis: Spot emerging topics and viral patterns --- ## ❓ FAQ Q: Do I need residential proxy? A: No! The scraper works reliably without proxy for most use cases. All 10 fields populate consistently (95-100%) without proxy. Enable proxy only for high-volume scraping or specific geo-targeting needs. Q: What about Shorts and live videos? A: Toggle includeShorts to control Shorts inclusion. Live/live-replay videos are auto-detected via type field. Q: Can I filter by date? A: Yes! Use dateFrom and dateTo (YYYY-MM-DD). Note: Date filtering only applies to Search Keywords, not Direct URLs. Q: Can I target a specific country/language? A: Yes! Set regionCode and language. For stronger geo-targeting, enable useResidentialProxy and set proxyCountryCode. Q: How do I bulk upload URLs? A: Upload a text file (one URL per line) or provide a requestsFromUrl pointing to a remote text file. Q: Why are some fields removed compared to v2.4? A: We optimized for discovery speed and reliability. Fields like shortDescription, thumbnailUrl, isLiveContent, category, tags, commentCount, and captions were removed to focus on minimal discovery fields. The current 10 fields provide just enough data to identify interesting videos for deeper analysis, with 95-100% reliability. --- ## 🛠️ Technologies & Architecture Built with modern web scraping tools for maximum performance and reliability: - Browser Engine: Puppeteer (headless Chrome) - Full JavaScript execution - Framework: Crawlee - Enterprise-grade crawling with queue management - Runtime: Node.js 18+ - Fast async processing - Extraction: Direct parsing of YouTube's internal APIs (ytInitialData, ytInitialPlayerResponse) - Anti-Detection: Advanced fingerprinting, human-like behavior, smart request handling - Optimization: Resource blocking (video streams, fonts, ads), parallel processing, intelligent timeouts Why These Technologies? - ✅ Reliable data extraction from complex single-page applications - ✅ Efficient handling of dynamic content and lazy loading - ✅ Automatic retry logic and error recovery - ✅ Scalable architecture for high-volume scraping --- ## 📋 Best Practices 1. Start small: Test with maxResultsPerQuery: 10 2. Filter early: Use dateFrom/dateTo to narrow results 3. Bulk wisely: Group URLs by topic/channel for better performance 4. Proxy optional: Only enable for high-volume or geo-specific needs 5. Export: JSON/CSV/Excel to your datastore, Google Sheets, or S3 --- ## 📜 Changelog v2.5 (Current - Production Ready - Discovery Release) - ⚡ 2x faster extraction (~2-3s per video vs 5-6s) - ✅ Works without residential proxy (95-100% reliability) - 📊 Optimized to 10 minimal discovery fields (from 30+) - 🚀 79% code reduction (34KB vs 165KB) - 💰 Zero artificial delays (error-based backoff only) - 🎯 Flat field structure (channelId, channelHandle) - 📅 Date range filtering for search keywords - 📁 Bulk URL upload via text file or remote link - ⚡ Script parsing optimization (early exit, max 5 scripts) - 🎯 Discovery-focused: lightweight fields for fast video identification v2.0 - Caption tracks in output - Richer channel fields - Improved localization --- ## 🤝 Compliance - Intended for legitimate research & business intelligence - Collects only public YouTube data - Respect YouTube's Terms of Service - Users responsible for compliance with applicable laws --- ## 💬 Support - Issues: Report via GitHub or Apify support - Feature requests: Open an issue with your use case - Documentation: See /docs folder for detailed guides --- Built with ❤️ for performance and reliabilityCategories
Common Use Cases
Market Research
Gather competitive intelligence and market data
Lead Generation
Extract contact information for sales outreach
Price Monitoring
Track competitor pricing and product changes
Content Aggregation
Collect and organize content from multiple sources
Ready to Get Started?
Try Youtube Video Finder now on Apify. Free tier available with no credit card required.
Start Free TrialActor Information
- Developer
- coregent
- Pricing
- Paid
- Total Runs
- 110
- Active Users
- 36
Related Actors

Web Scraper
by apify

Cheerio Scraper
by apify

Website Content Crawler
by apify

Legacy PhantomJS Crawler
by apify
Apify provides a cloud platform for web scraping, data extraction, and automation. Build and run web scrapers in the cloud.
Learn more about ApifyNeed Professional Help?
Couldn't solve your problem? Hire a verified specialist on Fiverr to get it done quickly and professionally.
Trusted by millions | Money-back guarantee | 24/7 Support